如何使用正则表达式去掉HTML标签
HTML是Web页面设计中必不可少的技术,是Web页面中内容展示的关键。但有时候我们需要提取其中的纯文本内容,这时就需要去掉HTML标签。本文将介绍如何使用正则表达式去掉HTML标签。
HTML标签是由尖括号包括的。在HTML标签中,有很多属性用于定义元素的特性,如class和id等。在使用正则表达式去掉HTML标签时,需要注意不仅要去掉标签,还要去掉标签中的属性。
具体的正则表达式如下:
/<[^>]+>/g
其中,/表示正则表达式的开始和结束;大于号和小于号表示HTML标签的开始和结束;1表示不匹配>的任何字符;+表示匹配的字符可以重复一次或多次;/g表示全文查找,而不是一次查找。
例如,要去掉以下HTML代码中的所有标签:
<!DOCTYPE html>
<html>
<head>
<title>HTML标签测试</title>
</head>
<body>
<h1>我们来测试一下HTML标签去除吧!</h1>
<p>这是一个段落。</p>
</body>
</html>
可以在JavaScript中使用以下代码:
var html = '<!DOCTYPE html><html><head><title>HTML标签测试</title></head><body><h1>我们来测试一下HTML标签去除吧!</h1><p>这是一个段落。</p></body></html>'; var pureText = html.replace(/<[^>]+>/g, ''); console.log(pureText);
上述代码将输出去除HTML标签后的纯文本内容:
HTML标签测试我们来测试一下HTML标签去除吧!这是一个段落。
这样,我们就成功地去除了HTML标签。在实际使用过程中,还需要注意以下几点:
- 正则表达式仅适用于HTML标签的纯文本内容,不适用于标签中的JavaScript代码和CSS样式等。
- 有些HTML标签是可以使用属性值指定内容的,例如<img>标签的alt属性,这些内容也不能被正则去掉。
- 如果HTML标签中包含的内容是字符实体(character entity),例如<和>,这些实体需要在正则表达式中进行替换,否则将无法正确去除标签。
除此之外,还可以使用专门的HTML解析库来提取HTML标签,例如Cheerio。但无论使用哪种方法,我们都需要保持警惕,确保提取出的文本内容是准确的、符合预期的。
- > ↩
以上就是如何使用正则表达式去掉HTML标签的详细内容!
相关内容
-
css判断某个标签不包含某个属性
你可以使用以下的CSS选择器来判断某个标签不包含某个属性:/*选择不包含某个属性的标签*/tag:not([attribute]){/*CSS样式*/}例如,如果你想选择所有不...
-
js截取字符串的几种方法
在JavaScript中,你可以使用多种方法来截取字符串。下面是一些常用的字符串截取方法:使用 substring 方法:letstr="Hello,World!";letsu...
-
js的indexOf方法介绍
indexOf 方法是JavaScript中用于查找数组中指定元素的位置的方法。该方法可以用于字符串和数组。对于数组:indexOf 方法返回指定元素在数组中第一次出现的位置(...
-
正则表达式中的.*和.*?的区别是什么?()
在正则表达式中,.* 和 .*? 是两种常见的通配符模式,用于匹配任意字符序列。它们的区别在于贪婪匹配和非贪婪匹配的方式。.* 贪婪匹配:. 匹配除换行符外的任意字符。* 匹配...
-
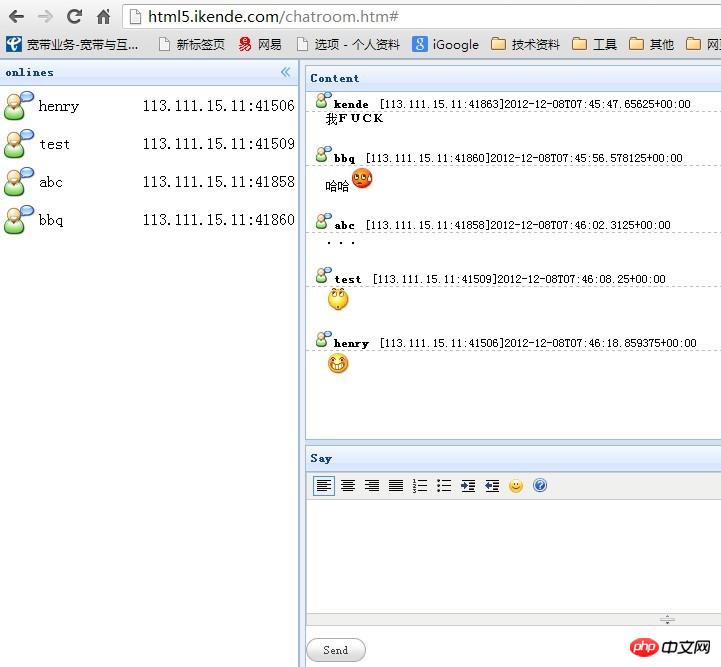
HTML5-WebSocket实现聊天室示例
本篇文章主要介绍了HTML5-WebSocket实现聊天室示例,具有一定的参考价值,感兴趣的小伙伴们可以参考一下。在传统的网页实现聊天室的方法是通过每隔一段时间请求服务器获取相...
-
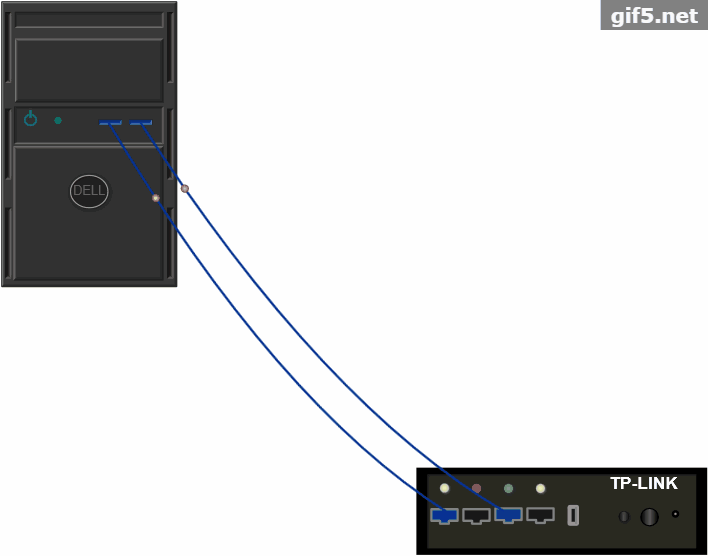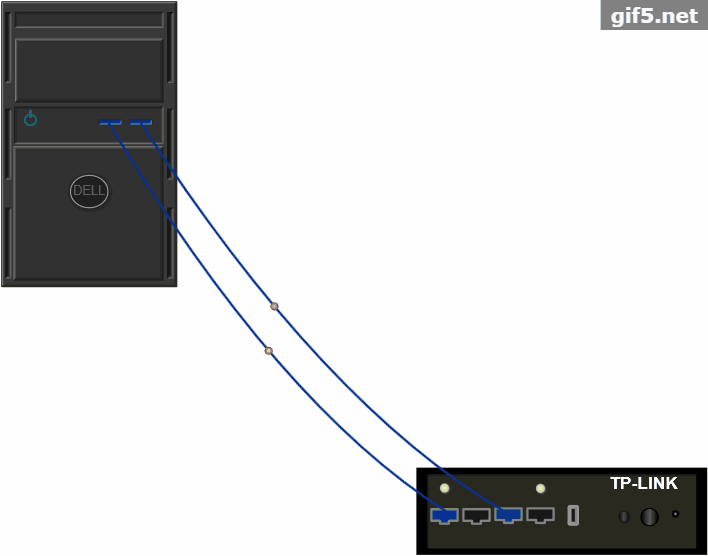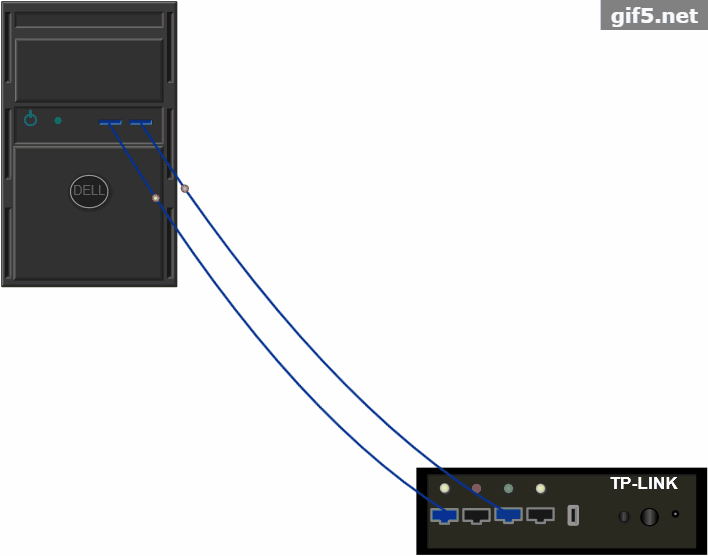
快速搭建TP-LINK电信拓扑设备面板基于HTML5的实现方法
今天我们以真实的TP-LINK设备面板为模型,完成设备面板的搭建,和指示灯的闪烁和图元流动。1、TP-LINK面板我们从TP-LINK的设备面板开始,设备面板的示意图如下:...
-
Android使WebView支持HTML5 Video全屏播放的方法分享(图)
1)需要在AndroidManifest.xml文件中声明需要使用HardwareAccelerate,可以细化到Activity级别,如果不需要的View可以声明不要用加速,...
-
如何在网站上添加谷歌定位信息
如何在网站上添加谷歌定位信息?下面小编就为大家带来一篇在网站上添加谷歌定位信息的实现方法。希望对大家有所帮助。一起跟随小编过来看看吧我们可以很容易地使用HTML5导航对象获取当...
-
li inside-block在IE11换行无效的原因
近日在做一个网页标签列表,要求不能换行,一开始以为比较容易,三两下就把代码写完了,并且在Firefox和Chrome浏览器测试通过,不过,在IE11一看,却出人意料的没有达到预...

-
\9和\0可能hack IE11\IE9\IE8无效原因详解
每次设计一张网页或一个表单,都被各种浏览器的兼容问题伤透脑筋,尤其是IE家族。在做兼容性设计时,我们往往会使用各种浏览器能识别的独特语法进行hack,从而达到各种浏览器下显示正...